One of the major highlights at Dreamforce was definitely the announcement of Salesforce Genie. We have seen a lot of fancy and easy architectural drawings, but what does it exactly do?
Salesforce Genie?
Salesforce Genie is a real-time platform which enables companies to meet their customers right where they are. This by harmonizing data that’s updated every millisecond. A highly personalized customer experience, delivered in real-time.
Across different industries, companies can leverage a unified profile and real-time data to deliver more personalised experiences. On multiple occasions milliseconds make all the difference. The cost of not keeping up could be poor social media reviews, profit loss, efficiency, and more.

Let’s dig a little deeper
As Salesforce experts, we needed to deep-dive into the real architectural picture of Salesforce Genie. In this article we will explain in an easy to understand way. Before explaining Genie (a hyper-scale platform), let’s start with the layered architecture of Salesforce Core.
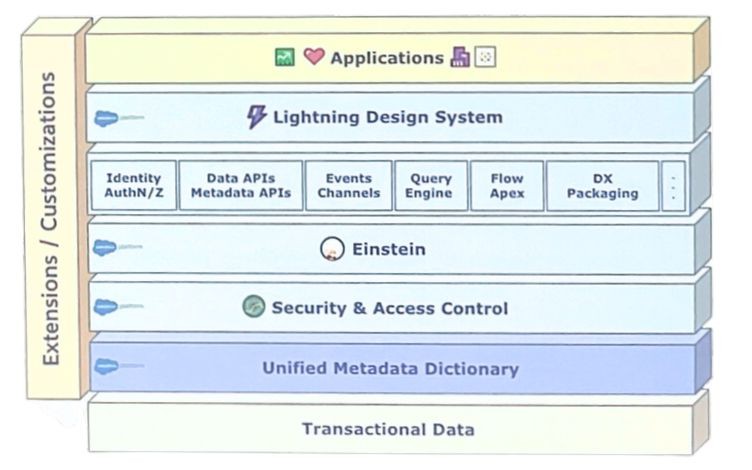
On the bottom of the diagram we find the data (transactional) layer. This is the traditional relational database that every Salesforce org shares with all tenants of the instance. In that database, you store the data from the standard objects (Account, Contact, Opportunity,…) and custom objects. The main advantage is that data is physically stored in the database. Thus making the data easy accessible for all your queries, triggers, flows and process automations.
Above the data layer you find:
- A “Unified Metadata Dictionary” which describes the data structures to enforce data integrity (e.g. a number field must contain a number) when saving records.
- “Security & Access Control” to ensure data is only visible to the relevant users in a specific org.
- “Einstein” the AI layer, which can leverage AI models to drive insights.
All layers above (Lightning Design Systems, Applications, Flow Apex, …) are the three top layers that we, as consultants, architects and customers, interact with daily.
This background information is crucial to explain where Genie’s “real-time” data sits.
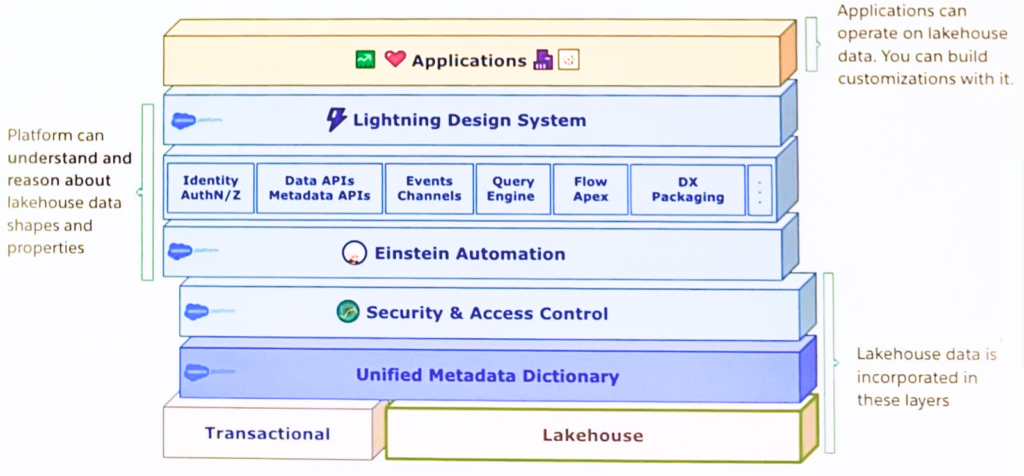
Salesforce has embedded a new “data lakehouse” layer to its platform which stands beside the traditional data layer.
So, what is a “data lakehouse”?
A data lake is a system or repository of data stored in its natural/raw format. It is usually a single store of data including raw copies of source system data, sensor data, social data etc. and transformed data. These are used for tasks such as reporting , visualisation, advanced analytics, machine learning and realtime queries. A data lake can include structured data from relational databases(rows and columns), semi-structured data (CSV,XML,JSON,..) , unstructured data (emails, PDF,..) and binary data (images, audio, video,..). A data lake can be established “on premises” (within an organisation’s data centers) or “in the cloud”.
– Source: Wikipedia
So by adding a new (data) lakehouse layer, you now get the ability to store significantly larger volumes of data. This while maintaining some benefits of traditional relational databases like ACID (Atomicity, Consistency, Isolation, and Durability) transactions. But that’s not all. Since the layer is embedded in the core of the platform, we have the possibility to use the data to drive automation and run queries. Moreover we can use data pipelines to prepare new datasets without the need of any ETL (Extraction, Transformation and Load) and connect it to Salesforce BI applications (CRM Analytics, tableaux) and AI Layers.
So, how do we get the needed data into this layer and what tools will be available to support the import?
There are essentially 3 ways:
1. Real-time (or near real-time – milliseconds to minutes) using web and mobile applications to perform real-time ingests or MuleSoft to ingest data via streaming.
2. Batch ingest (minutes to an hour) either through batch ingestion from Salesforce applications like Marketing, Commerce or core products like Sales and Service. But it is also possible to bring in data from other third-party sources (through MuleSoft or direct API’s)
3. Bring your own Data Warehouse. If you happen to have, for example, an existing Snowflake deployment, you can mount your data lake/warehouse with zero copies into Salesforce Genie. Thanks to Genie we can act on data that doesn’t even reside within Salesforce.
It’s always important to have the data and use it in the Salesforce concept. But you maybe also need to extract data from this data lake.
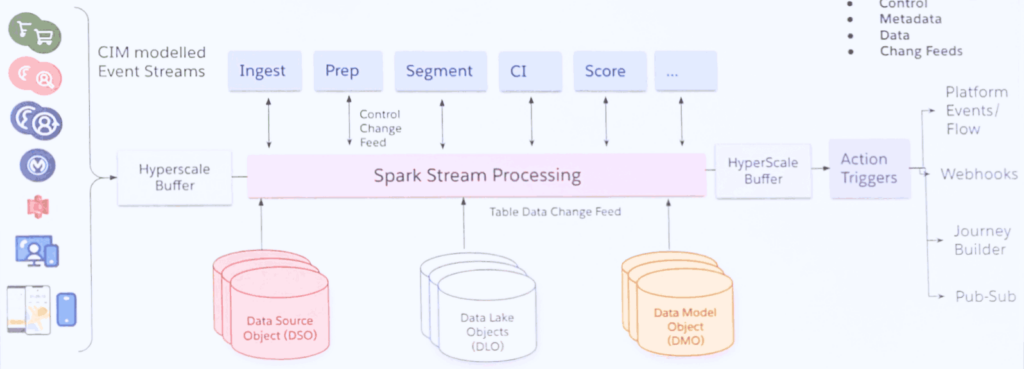
When dealing with very large data volumes (billions of rows) it’s important to process this data efficiently. Salesforce (Genie) is leveraging Apache (Spark), a “general-purpose distributed data processing engine, suitable for use in a wide range of circumstances, like big data workloads.”
Fundamentally, as data is being processed, the output triggers actions which result in platform events, webhooks and the triggering of journeys which will help us automate business processes and logic.
Being able to access large data directly within Salesforce without the need for more connectors, creates quite some opportunities. The ability to query and access large data volume in real-time natively in Salesforce core is very powerful. Finally the ability to trigger flows to execute when data changes, whilst maintaining CRUD (create, read, update, and delete) and FLS (field level security), is great for consultants and developers.
Hopefully this article was helpful to better understand the structure of Genie.
